
先日、歌ってみた動画を上げました。
みんな〜もう聞いたかい?\( 'ω')/
この中の背景イラストは、最近話題のStable Diffusionで生成しました。
今回は、その生成手順と、そこで学んだコツについて書いてみたいと思います。
Stable Diffusion web UI導入
以下の記事を参考にしました。
とてもわかりやすいです。
基本的に、ほとんど複雑なコマンドは使わず、流れに沿ってインストールしていけば良いので、かなり楽でした。
生成の流れ
概要
イラストは海と人物、別々に作って、後から重ねています。
最初はまとめて作ろうとしたのですが、全然思い通りにならなかったので、分けました。
txt2imgというプロンプト(=文章)から画像を作る機能と、
img2imgという画像をベースに画像を作る(ただし、ここにテキストも追加できます)機能と、
inpaintという細部修正の機能を使い分けていきます。
大まかな流れとしては、
まずtxt2imgという機能で、文章からざっくり画像を生成し、
できた画像をimg2imgという機能に入れて、よりイメージに近い画像を再生成します。
そして、微調整をinpaintで行います。
文章から画像の生成
最初の段階では、こんな感じで、思っていたのと全然違う絵ばかり生成されて、心が折れかけました笑
 |
| え⁉笑 |
 |
| 誰!笑 |
思っていたのとは違うけど、エモいっ!という画像もできました。


【うまく作るコツ】
まず、学習モデル(model.ckpt)の選定が大事になります。
アニメっぽい画像が得意なモデルもあれば、写実画っぽい画像が得意なモデルもあります。
私はとりんさまAIのモデルを使用して作成しました。
またLexicaというStable Diffusionで使うプロンプトを検索できるサイトを使って、自分のイメージに近い画像を探し、そこからプロンプトに使う文言を拾って使ってみることです。
例えば "sea sky night"で検索すると、かなりバリエーション豊かな画像が出てきます。
写真っぽく?絵画っぽく?
ぼんやり霧のかかったような雰囲気?パッキリと色が鮮明な画像?
こんな感じにしたい!というイメージに近い画像を選んでみます。

画像を選ぶと、生成プロンプトを確認できます。

いい感じのプロンプトを見つけたら、それを元に生成してみましょう!
画像から画像の生成
海の画像は、txt2imgだけでかなりいいものができたのですが、人物の方はめちゃくちゃ苦戦しました。

はっきり頭の中にイメージがあって、絵を描ける人は、自分で大まかなイラストを描いて、img2imgに入れても良いでしょう。
その場合、こちらの記事もかなり参考になります。
私の場合は、txt2imgで作った画像をimg2imgに放り込むことで、大まかな構図(男性と女性が手を繋いで立っている)は同じだけれど、もう少し表現のバリエーションを模索しました。
ここからはもう、ひたすらガチャを回していく感じです。
その中で奇跡的にできた構図がこれ。

女性の手がおかしかったり、男性の服から謎のぴらぴらが出ていたりしますが、このあたりは
img2imgではなく、次の段階でさらに細かい調整をかけていくことにします。
(img2imgで再調整もしてみたのですが、かえって崩れてしまうことが多かったです)
【うまく作るコツ】
調整のやり方の勘所は、こちらの記事がわかりやすかったです。
基本的にimg2imgで触るのは、赤線を引いた3か所です。

サンプル画像から反復して画像を再生成するステップ数を決められます。
50以上でかなり安定しそう。私は60にしていました。
あまり上げすぎると、時間がめちゃくちゃかかります。
※CFG Scaleという出力をプロンプトにどれだけ近づけたいかを指定する数値のサイズに応じて、この適切なステップ数は変わるそうなのですが、一旦CFG Scaleは触っていません。
どんなふうに変わるのかは、こちらの画像が詳しいです。
 |
| Redditより抜粋 |
Batch count
一度に何枚の画像を出力するか決める数です。
多ければ多いほど時間がかかるので、これはマシンスペックと相談してください。
私は5~6に設定していました。
Denoising strength
元画像にどれくらいイメージを寄せるかを決める肝になります。
基本的に、この数値を一番細かく触ります。
0.4~0.65あたりにすると、いい感じに原型を保ちつつ、バリエーション豊かな画像を出力してくれます。
これより小さい値だと、元画像そっくりで、細部の変更にとどまり、
これより大きい値だと、元画像の構図を丸ごと無視したような画像ができます。
この辺りの調整はお好みで。
できた画像はこまめに保存しておきましょう。
途中でぐちゃぐちゃになった時に、戻りやすいので。

Settingsで自動保存するようにセットしておくこともできます。

そうすると、自動でstable-diffusion-webui/outputsというフォルダに保存されていくはずです。
画像の調整
大まかな構図ができたら、inpaintという機能を使って、細部の修正をします。
inpaintは、画像の一部を修正できる機能です。
服をもう少しおしゃれにしたいとか、腕から腕が生えている(?)などを直しました。
 |
| 最初の画像から、二人の髪型をちょっと直したもの |
【うまく作るコツ】
欲張らないことです笑
ここも、そこも、いっぺんに直してしまおうとあちこち塗りつぶすと、ぐしゃぐしゃになることが多いです。
本当に少しずつ(服の一部、腕の一部だけなど)根気よく直すのが大事です。
基本的に触るのは、以下の赤い部分です。

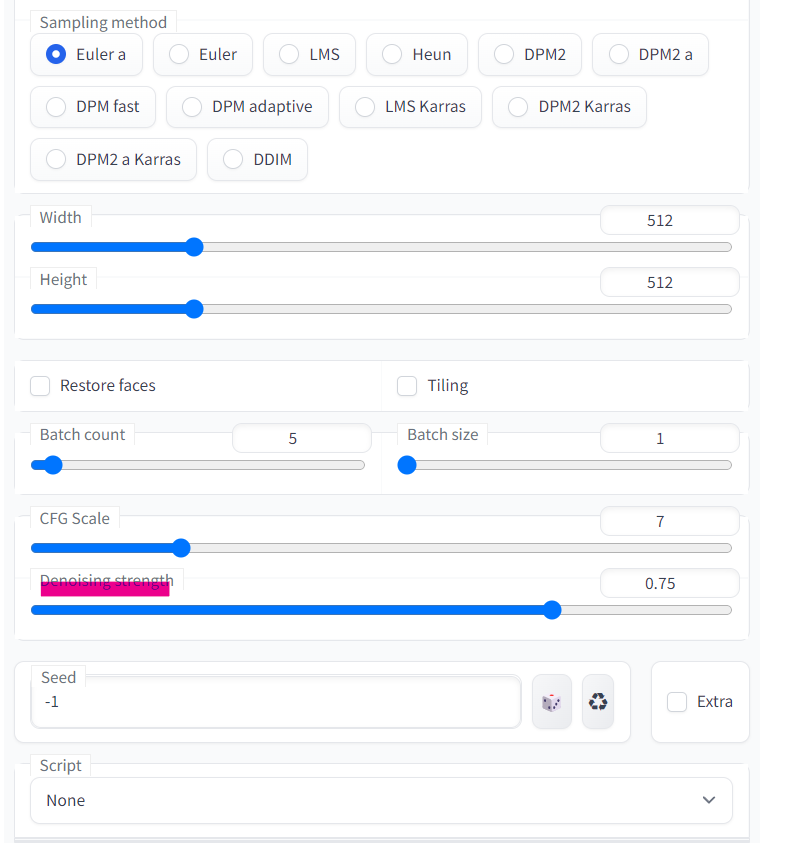
調整したい部分を選択する際、選択範囲をどれくらい広げるかという数値設定かと思われます。
私は1に設定しています。
多分、数値を大きくするほど、選択範囲の影響が広がっていくのだと思う。





よく見ると、人物の方は、少しゴミがあったり、顔がはっきりしていなかったりするのですが、動画の中ではそこまで大きく表示する予定がなかったので、これでOKとしました。
Masked content
fillは、そこを完全に塗りつぶしたい=消したい場合に使います。
originalは、元々の画像を参照して画像を再生成してくれます。
例えば、手が三本生えていて、完全に消したい時にはfill、
画像を踏襲しながら、服の雰囲気を変えたい場合はoriginal、
という感じで使い分けましょう。
Sampler Steps
上で説明したので割愛。
60くらいで設定。
Batch count
上で説明したので割愛。
5〜6くらいで設定。
Denoising strength
上で説明したので割愛。
元画像にどれくらい近づけるかで数値を決めましょう。
また、ここで自分で手を加えて、その画像を元にinpaintにかけるのもありです。
例えば、CLIP STUDIO PAINTでスカートの部分のみ選択して、色調補正をかけておき、その画像を元に生成しました。
 |
| スカートの色を、CLIP STUDIOで色調補正 |
 |
| そしてスカート部分を選択して、inpaint実行した結果。 より素材がふわっとして、足の形がわかるようになった |
人物については、表情をうまく作るのがどうしても難しかったので、ある程度、自分でCLIP STUDIO PAINTで描き込みしました。
サイズの調整
inpaintのSD upscaleでまず画像を拡大します。
ちょっとわかりにくいのですが、画面を下にスクロールし、Scriptの中のSD upscaleを選択します。

Sampling method: Euler a
Denoising strength: 0.2(~0.4)
で実行することが公式で推奨されています。
私は、SD upscale内の他の値は、特に触らずに実行しました。
最後に、Extrasタブの中のScale toを使って、画像をお好みのサイズに拡大出力して、無事に完成です。
【うまく作るコツ】
Extras > Scale toの中のupscalerにも色々種類があり、微妙に出力結果が変わります。

例えば以下は、同じ画像をUpscaler 1とUpscaler 2の組み合わせを変えて出力した結果なのですが(他の値はいじっていません)、
後者は星がノイズ判定されて消されており、のっぺりしてしまいました。


いくつか組み合わせを試してみて、お好みで選んでみてください。
完成
こちらが完成した絵です。わ〜い!


人物の方は、removebgというサービスを使って、背景削除しました。
一瞬で、しかもめっちゃ綺麗に画像の背景を消してくれて、すごく便利でした。
しかも無料(50回まで)。

その他、動画内の背景サイズの変更(少し横長にした)や、足元の波紋、流れ星、明るさなどは、CLIP STUIO PAINTで別途追加・修正しました。
全体的な所感
初めてのAI画像生成、ツールの癖が強くて、最初は苦戦するところも山ほどありましたが、やっていくうちにだんだんコツが掴めてきました。
完璧な理想の絵を、一発で生成するのはかなり難しいです。
相当なプロンプト遣いにならなくてはならない。
そのため、txt2imgとimg2imgで、とにかくざっくりと構図が決まったら、そこからはinpaintで細かく調整を重ねていくのが吉です。
一回のGenerateで複数パターン生成できるので(たくさん作る分だけ時間はかかるのですが)、ガチャみたいで楽しいです。
面白くて、時間が無限に溶けますよ。
みんなもLet's AI画像生成!٩( 'ω' )و
コメントを投稿
別ページに移動します